Resumo
Este artigo explora as estratégias de personalização algorítmica do aplicativo de streaming musical Spotify, com enfoque especial na forma como a empresa concebe e anuncia suas ferramentas de recomendação segmentada. A promessa de oferecer conteúdos de acordo com os gostos, desejos e necessidades de cada usuário fundamenta-se na premissa de que seria possível “conhecer” aspectos da identidade e individualidade através dos dados de interação online, ou seja, de que somos o que ouvimos. Nesse sentido, a pesquisa considera que a datificação se associa a alguns deslocamentos históricos nos regimes de subjetivação contemporâneos. Trata-se de um artigo ensaístico, que se debruça sobre materiais institucionais do Spotify e dois casos emblemáticos de personalização, a playlist Descobertas da Semana e a campanha Só Você, apontando algumas contradições que atravessam a promessa de ultrapersonalização. Mais do que questionar se estes sistemas acertam em suas previsões e recomendações, interessa pensar seus efeitos performativos, isto é, como eles influenciam a construção de sujeitos datificados e identidades algorítmicas.
1. Introdução
O aplicativo de streaming Spotify se apresenta como uma plataforma musical que oferece a seus usuários uma experiência personalizada, entregando conteúdos “sob medida”, que seriam direcionados com base nos gostos, interesses e hábitos de cada um. Seguindo uma tendência mais ampla das plataformas digitais e da publicidade contemporânea, o Spotify mobiliza uma enorme infraestrutura algorítmica de coleta de dados para apresentar uma experiência customizada de uso do aplicativo, com sistemas de recomendação de músicas e podcasts e desenvolvimento automatizado de playlists.
Neste ensaio, buscamos discutir como essa promessa de ultrapersonalização se sustenta a partir da premissa de que os algoritmos são capazes de nos conhecer até melhor do que nós mesmos, propagandas por entusiastas da tecnologia, teóricos e pelas próprias plataformas digitais. A partir de afirmações de peças publicitárias, campanhas e artigos científicos, veremos como o Spotify constrói a ideia de que “você é o que você ouve”1 e de que “as músicas e podcasts que as pessoas escutam revelam quem elas são”2. Na narrativa do aplicativo, a análise preditiva de padrões de consumo a partir de dados como cliques, curtidas, músicas tocadas e puladas daria acesso a algum tipo de intimidade ou individualidade dos sujeitos.
O intuito deste texto é analisar, ainda de modo exploratório, como os processos de datificação3 se associam a uma série de reconfigurações topológicas que vêm ocorrendo no nível das subjetividades (Bruno, 2013). Aqui, interessa especialmente identificar alguns deslocamentos históricos nos regimes de subjetivação contemporâneos. Se há algum tipo de individualidade capaz de ser “revelada” por meio da análise de rastros digitais, ela apresenta características muito distintas daquela cultivada no mundo moderno, ligada a uma dimensão privada, profunda e opaca. A partir dos trabalhos de Fernanda Bruno (2013) e Paula Sibilia (2016), discutiremos como a topologia da subjetividade, antes circunscrita ao espaço privado, se volta cada vez mais ao espaço aberto dos meios de comunicação.
Considerando as dificuldades de pesquisar algoritmos e contornar as chamadas “caixas-pretas”, o percurso metodológico da pesquisa envolveu alguns desafios. Algumas pistas puderam ser encontradas a partir do trabalho de Kitchin (2017), como a ideia de realizar uma análise discursiva de como os algoritmos são imaginados e narrados por aqueles que os criam e promovem (Kitchin, 2017, p. 25). Uma vez que não era possível acessar propriamente os códigos algorítmicos do Spotify, buscamos levantar um conjunto de materiais que nos pudessem fazer entender como as estratégias de personalização são concebidas e anunciadas pela plataforma, isto é, que tipos de discursos são mobilizados em conjunto com os aparatos técnicos.
Tendo em vista esse objetivo, o percurso metodológico da pesquisa envolveu três etapas. Em primeiro lugar, um mapeamento exploratório do aplicativo Spotify, com foco na arquitetura de plataforma e nas principais ferramentas de recomendação e personalização. Em segundo lugar, levantamos conteúdos de sites institucionais da plataforma – como o Spotify Advertising, Spotify Engineering, Spotify Research e Newsroom – assim como artigos e publicações científicas de pesquisadores ligados à empresa. Nesses textos e publicações, procuramos observar especificamente o que era dito sobre as estratégias de personalização e os sistemas de recomendação algorítmicos. Por fim, escolhemos dois casos específicos para nos desdobrar com maior atenção: a Descobertas da Semana, uma das primeiras playlists personalizadas do aplicativo, e a campanha Só Você, que tinha como intuito “celebrar seu estilo único de escuta”.
A partir de um breve panorama histórico, o artigo aponta como a personalização algorítmica adquiriu uma centralidade no aplicativo Spotify e se complexificou ao longo dos anos. Mas para além do caráter técnico dos sistemas algorítmicos, apontamos que a empresa mobiliza também uma certa retórica da personalização. Na linguagem utilizada e na forma como as funcionalidades são anunciadas, o Spotify reafirma constantemente que os conteúdos são feitos unicamente para cada usuário, que a plataforma conhece muito bem seu jeito de escutar e, por isso, as recomendações são precisas e certeiras. De certa forma, os rumos da pesquisa seguem a inquietação de que o Spotify seria capaz de conhecer ou entender seus usuários.
Como veremos, essa retórica encobre um sistema de perfilamento de usuários no qual nossas individualidades são bastante insignificantes. A racionalidade algorítmica se alimenta de dados infraindividuais e anonimizados, desassociados dos indivíduos a que se referem, privilegiando muito mais padrões comportamentais em larga escala do que especificidades de cada um (Rouvroy e Berns, 2015; Bruno, 2013). A personalização algorítmica, neste sentido, é marcada por um paradoxo no qual o você para quem as recomendações se direcionam é simultaneamente específico e generalizável (Chun, 2016; Lury e Day, 2019), refletindo padrões supraindividuais de hábitos e comportamentos.
Ao final do texto, a partir de alguns trabalhos dos chamados estudos críticos de algoritmos (Gillespie e Seaver, 2016), discutiremos os efeitos performativos da lógica algorítmica (Introna, 2013; Mackenzie, 2005; Bucher, 2017, Bharti, 2021). Mais do que “acertar” quais são nossos desejos e gostos musicais, o valor destes sistemas está em projetar potencialidades, suscitando estas vontades de consumo que alegam revelar. Considerando o caso Spotify, levantaremos a hipótese de que a retórica da personalização possui, portanto, um papel performativo. Incentivar os usuários a acreditarem que seus dados de interação representam uma verdade do sujeito – isto é, que o Spotify “os conhece” muito bem – pode possivelmente contribuir para o próprio funcionamento dos sistemas de recomendação, isto é, para que as pessoas se reconheçam naquelas recomendações e as acatem. Assim, este ensaio busca refletir sobre o papel performativo da personalização, que carrega a tendência de nos conduzir a performar as identidades algorítmicas que nos são atribuídas, acarretando a produção de sujeitos cada vez mais previsíveis, influenciáveis e iguais uns aos outros.
2.Uma breve história do Spotify
Quando foi lançado, em 2008, o aplicativo Spotify tinha a proposta de ser uma grande biblioteca musical, um serviço fácil de usar, rápido, gratuito e com acesso a quase todas as músicas que você conhece. “Você procura, você encontra.… O que você quiser, quando você quiser”, dizia o vídeo de lançamento da empresa4, que buscava fornecer uma alternativa de consumo musical ao mesmo tempo cômoda para os usuários e rentável para a indústria, naquele momento muito marcada pela pirataria online.
No livro Spotify Teardown: Inside the Black Box of Streaming Music (2019), os autores explicam que, neste início, a arquitetura da plataforma era completamente centrada em torno da barra de pesquisa, sendo o usuário concebido como alguém que sabia exatamente o que queria ouvir (Eriksson et al, 2019). Naquela época, as recomendações personalizadas não eram consideradas um recurso essencial dos serviços de streaming e até o final de 2011 a única ferramenta de recomendação presente na plataforma era relativamente controlada pelo usuário, que selecionava manualmente os gêneros musicais ou décadas que gostaria de escutar.
É na medida que outros serviços de streaming vão surgindo, tanto de música como de vídeo, que se torna um consenso na indústria que as empresas passariam a disputar pelos melhores recursos de recomendação. Com uma quantidade massiva de músicas se acumulando e poucas ferramentas para auxiliar usuários a navegar pelo app, o Spotify passa a ser criticado por ser apenas uma grande base de dados musical – o que antes era uma virtude, torna-se um defeito (Eriksson et al, 2019). O problema da “abundância de escolha” passa a ser enfrentado de forma mais séria no final de 2012, quando o CEO Daniel Ek introduz os primeiros mecanismos de personalização.
Estes primeiros sistemas algorítmicos do Spotify se baseavam sobretudo nas técnicas de filtragem colaborativa, que consistem em uma análise do comportamento dos milhões de usuários na busca por padrões de consumo. O número de vezes que uma pessoa tocou determinada música, álbum ou playlist, o histórico de buscas, as músicas curtidas e puladas, assim como diversos outros dados comportamentais de uso são entendidos como um feedback implícito sobre as preferências de cada um. Agregados, os dados são categorizados a partir do seguinte pressuposto: se dois usuários escutam o mesmo conjunto de músicas, seus gostos provavelmente são parecidos; e se duas músicas são ouvidas pelo mesmo grupo de usuários, elas provavelmente têm alguma semelhança sonora (Dieleman, 2014).
Ao invés de categorizar as pessoas a partir de informações predeterminadas como grupos demográficos (idade, nacionalidade) ou dados de localização, os mecanismos de filtragem colaborativa se baseiam exclusivamente nos padrões de consumo, partindo da simples premissa de que clientes que compartilham algumas preferências também compartilharão outras. Neste cálculo, “gostar” significa “ser como”5, de modo que o direcionamento personalizado de conteúdos para um usuário específico é alcançado a partir de uma aproximação das relações entre gosto e semelhança, entre preferência e similaridade (Lury e Day, 2019). Ou seja, usuários receberiam recomendações de músicas ouvidas por outras pessoas com padrões de consumo similares aos seus.
O Spotify, entretanto, rapidamente percebe as limitações de construir um sistema algorítmico baseado exclusivamente neste mecanismo: há pouco espaço para diversidade. As listas acabam recomendando principalmente as músicas mais populares e conteúdos heterogêneos, com os mesmos padrões de uso, uma vez que há mais dados relacionados a estas faixas. Por sua vez, as músicas novas ou pouco populares deixam de ser recomendadas (Dieleman, 2014; Galvanize, 2016).
A plataforma, então, buscou diversificar as fontes de informação para incorporar aos seus sistemas de recomendação. A aquisição em 2014 da empresa The Echo Nest, especializada em dados e inteligência musical, desempenhou um papel central nesse processo, permitindo que o Spotify avançasse também na análise acústica e do conteúdo das músicas.
Em 2015, é lançada a funcionalidade Descobertas da Semana, uma lista automatizada que entrega toda segunda-feira novas músicas que a plataforma infere como de possível interesse de cada usuário, de acordo com seus históricos pessoais prévios de consumo. Presente até hoje no aplicativo, essa playlist é um exemplo emblemático da personalização algorítmica no Spotify. Para além de ser uma funcionalidade extremamente elogiada pelos usuários, ela passou a figurar com a promessa central de que o aplicativo entende as preferências de cada um. Como diz uma publicação do site Spotify Advertising, “ouvintes dizem que a playlist Descobertas da Semana conhece eles melhor do que o próprio companheiro ou, ainda, melhor do que eles mesmos!”.
A personalização já não é mais uma boa opção apenas, ela é essencial. As Descobertas da Semana são adoradas porque são adaptadas ao gosto musical específico de cada ouvinte. Isso criou uma experiência de engajamento profundo para nossos usuários, que esperam que o Spotify perceba as preferências deles. Pode até parecer mágica: vemos constantemente os tweets em que os ouvintes dizem que a playlist Descobertas da Semana conhece eles melhor do que o próprio companheiro ou, ainda, melhor do que eles mesmos! (Spotify Advertising, 2020).
O sistema algorítmico da lista Descobertas da Semana trouxe uma tecnologia inovadora à época pela abordagem híbrida, que misturava três mecanismos: 1) filtragem colaborativa; 2) análise de áudio; 3) processamento de linguagem natural6 (Dieleman, 2014; Ciocca, 2017). A análise de áudio consiste na detecção de características como ritmo, tom, harmonia, batida, estilo e até mesmo “dançabilidade” de uma música, possibilitando a sugestão de outras que combinam bem com ela. Por sua vez, o processamento de linguagem natural envolve um mapeamento do que está sendo mencionado na internet, em blogs e redes sociais sobre determinados artistas, músicas e gêneros. Essa tecnologia agrupa palavras-chave e termos mais citados, com objetivo de compreender o que está em alta, de que forma as pessoas estão recebendo e interagindo com os conteúdos, além de mapear vetores culturais relacionados a cada tipo de música (Ciocca, 2017).
Desde o lançamento da Descobertas da Semana, os mecanismos de personalização do Spotify se multiplicaram e complexificaram, havendo cada vez mais investimento em análise semântica, sonora, bem como uma preocupação em aumentar a diversidade dos conteúdos consumidos. Pesquisadores da própria empresa se mobilizam para balancear engajamento e diversidade (Holtz et al., 2020), respondendo às críticas de que sistemas de recomendação criam “filtros-bolha” (Parisier, 2010), isto é, homogeneízam o consumo e dificultam o contato com conteúdos diversos.
Ainda assim, a lógica utilizada para categorizar a agrupar estes dados parece continuar sendo marcada pelos princípios de semelhança e familiaridade mencionados anteriormente: músicas do mesmo gênero ou com ritmos e batidas parecidas, que são frequentemente ouvidas em ocasiões similares ou que atraem grupos sociais e usuários com perfis semelhantes, entre outros critérios. Apesar do nome Descobertas da Semana sugerir que a playlist promove a diversificação, estudos apontam que as recomendações algorítmicas reforçam padrões existentes de consumo e desigualdades históricas, tanto de gêneros musicais como de nacionalidades, raça e gênero (Werner, 2020; Hesmondhalgh et al, 2023; Internetlab, 2023).
O problema da diversidade é central nas discussões sobre personalização algorítmica e amplamente discutido há mais de uma década, como no livro The filter bubble: what the internet is hiding from you (Parisier, 2010). Na maior parte dos casos, o design computacional automatiza uma determinada conceituação sociológica sobre o comportamento humano pautada na noção de “homofilia”, isto é, de que há uma tendência entre pares de se comportar de formas semelhantes (Chun, 2016). Por operarem nesta lógica homofílica e probabilística, sistemas de recomendação dificilmente entregarão algo que destoa do que cada um já gosta e já consome.
Como bem descreve Faltay (2020), a questão é que ao tomar a homofilia como um fenômeno natural, ela se torna uma profecia autorrealizável: “as redes algorítmicas irão apenas encontrá-la. Irão apenas ver padrões de valores similares, já que foram treinadas para identificar privilegiadamente” (Faltay, 2020, p. 149). Assim, a priorização da semelhança enquanto critério organizador deixa poucas oportunidades para o contato com o díspar, confrontos com o estranho ou para imprevistos, de modo que são cada vez mais reforçados gostos, ideias e pontos de vista já estabelecidos. Em última instância, o que se exclui são aqueles encontros capazes de nos deslocar de nossas certezas, de nossos hábitos e enraizamentos (Walter e Hennigen, 2021).
Na próxima seção, abordaremos como as estratégias de personalização também se relacionam com os objetivos comerciais do Spotify, atuando na retenção da atenção e no estímulo ao engajamento dos usuários.
3. O imperativo da personalização: “as pessoas não têm tempo para descobrir por conta própria”
Nos debruçaremos agora sobre materiais levantados a partir de alguns sites institucionais, como o Spotify Advertising7, Spotify Engineering8, Spotify Research9 e Newsroom10, de modo a compreender como a personalização é concebida e anunciada pela empresa. Neles, vemos que a personalização é reiteradamente legitimada pela promessa de comodidade e de uma experiência mais satisfatória com o aplicativo, uma vez que o usuário só receberia, segundo o Spotify, conteúdos que são de seu interesse. Oskar Stål, vice-presidente da equipe de personalização, explica que os engenheiros da plataforma perceberam que “você aproveita mais o Spotify quando descobre mais, e a maioria das pessoas não tem tempo para descobrir por conta própria”11.
Nessa fala, é interessante observar a argumentação sobre a falta de tempo. Em um mundo hiperconectado, marcado pela temporalidade acelerada e excesso de informação e estímulos, a atenção se tornou um recurso escasso (Caliman, 2012), valioso e desejado pelas empresas de tecnologia, que disputam pelo nosso tempo e energia para consumir conteúdos e anúncios (Bentes, 2019). Nessa dinâmica, apontada por vários autores como própria de uma economia da atenção, as plataformas elaboram os recursos algorítmicos de recomendação para garantir que os usuários consumam mais conteúdos e permaneçam conectados ao aplicativo. Gerando engajamento, as estratégias de personalização estão intimamente imbricadas com os objetivos de monetização das empresas, atuando como um diferencial competitivo.
Um estudo realizado pela Netflix, por exemplo, estima que as pessoas perdem interesse na busca por conteúdos em um tempo de 60 a 90 segundos, de modo que “o usuário ou encontra alguma coisa interessante ou o risco de ele abandonar nosso serviço cresce substancialmente” (Gomez-Uribe e Hunt, 2015, p. 2). Assim, os sistemas de recomendação operam com objetivo de entregar ao consumidor algo relevante em um tempo muito curto, evitando ao máximo que ele mude de plataforma. A eficiência destes sistemas, portanto, é medida justamente pela capacidade de capturar a atenção e produzir o engajamento dos usuários (Bentes, 2019).
Alguns documentos do Spotify corroboram essa hipótese. Em um site direcionado para anunciantes, a empresa confirma a ideia de que “quanto mais personalizada a experiência de streaming, mais nossos fãs se engajam”12. Dados da plataforma também indicam que usuários que utilizam a playlist Descobertas da Semana consomem o dobro de conteúdos quando comparados a usuários que não utilizam a ferramenta13, demonstrando que ela contribui para que as pessoas permaneçam conectadas ao app.
Consequentemente, a centralidade que os mecanismos de personalização adquiriram em plataformas como o Spotify está diretamente ligada a seus objetivos comerciais, uma vez que as métricas de engajamento se tornaram indicadores fundamentais para medir o sucesso e crescimento das empresas na indústria de software contemporânea. Assim, vemos duas facetas dos sistemas de recomendação: ao mesmo tempo que atuam como elemento que legitima um discurso de comodidade e conveniência para os usuários, eles também passam a atuar, na lógica das empresas, como “armadilhas” para capturar usuários inconstantes ou indecisos, como argumenta Seaver (2018).
Podemos observar isso também na própria arquitetura da plataforma. Como mostra a imagem abaixo, que apresenta a tela inicial do aplicativo, a primeira coisa a aparecer para o usuário são seis “estantes” com sugestões de álbuns, podcasts ou playlists de rápido acesso e também seções de “cartões”, nas linhas horizontais, com mais sugestões de conteúdos. Ambos são sugeridos a partir de um modelo de atalho (The Shortcut Model14), que tenta prever algum conteúdo familiar que o usuário possa gostar de escutar.
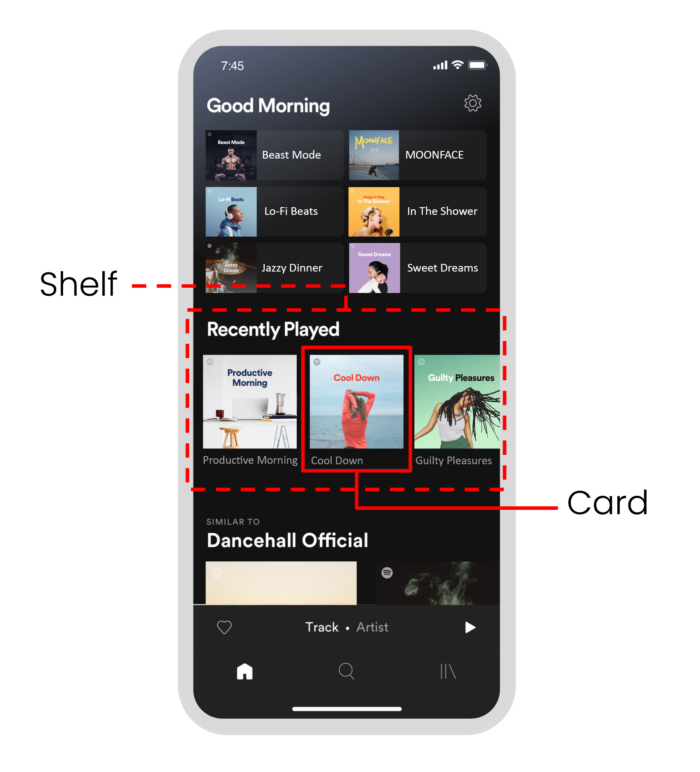
Essas recomendações não apenas se adequam a cada perfil de usuário, mas também ao horário do dia, uma vez que as preferências são altamente contextuais. As sugestões se adaptam ao estilo de vida de cada um, como por exemplo escutar podcasts no café da manhã e músicas animadas para fazer exercício físico. Além disso, a entrega de uma quantidade grande de recomendações logo na primeira página do app busca resolver justamente esta indecisão que muitos experienciam ao abrir o aplicativo.
No caso do Spotify, que trabalha com um modelo de negócios “freemium” (free + premium), os sistemas algorítmicos parecem operar em dois sentidos. Usuários que assinam o serviço mensalmente precisam ser convencidos de que a plataforma entrega um serviço melhor que os concorrentes. Já no caso dos que utilizam a versão do aplicativo gratuita, que impreterivelmente são expostos a ouvir anúncios, são os anunciantes que precisam ser convencidos que a plataforma é eficaz em entregar publicidades ao ouvinte certo, no momento e no tom adequados.
Como podemos ver na citação abaixo do site Spotify Advertising, a ideia de que a plataforma seria capaz de “entender” seus usuários através da inteligência de streaming é utilizada também como forma de legitimar seu potencial na entrega de anúncios segmentados:
O contexto é o que potencializa os anúncios em áudio digital. A inteligência de streaming do Spotify é tão avançada que reconhece os interesses, astrais e ocasiões dos ouvintes, ou seja, nós entendemos a pessoa que está do outro lado. Por isso, conseguimos passar a mensagem certa ao ouvinte no momento exato e no tom adequado (Spotify Advertising, 2021).
4.Reconfigurações da topologia da subjetividade
Na próxima seção, apresentaremos mais materiais do Spotify que corroboram a premissa de que os algoritmos seriam capazes de “entender a pessoa que está do outro lado” ou “nos conhecer melhor do que nós mesmos”. Conforme veremos, essa concepção deriva do argumento de que a análise preditiva de padrões de consumo seria capaz de revelar algum tipo de intimidade ou individualidade dos sujeitos, isto é, a ideia de que somos nossos dados.
Como exploramos neste ensaio, a construção dessa premissa se associa a algumas reconfigurações e deslocamentos históricos nos modos de subjetivação contemporâneos. Se há algum tipo de individualidade capaz de ser compreendida a partir de dados e modelos algorítmicos, é preciso considerar que o sentido destas ideias está distante daquele construído no mundo moderno.
Algumas pistas sobre essas transformações podem ser encontradas nos trabalhos de Paula Sibilia (2016) e Fernanda Bruno (2013) sobre o cenário recente de exposição da intimidade na Internet e na televisão. Ambas recuperam a genealogia do indivíduo moderno proposta por Michel Foucault para situar que a ideia do sujeito enquanto uma unidade, enquanto indivíduo dotado de uma identidade e uma subjetividade interior é algo produzido na modernidade, na relação com determinadas práticas e saberes.
No paradigma moderno, a verdade do sujeito estava associada a uma dimensão íntima, a uma interioridade privada e profunda, a um “mundo interno” que era próprio de cada indivíduo e opaco ao olhar alheio. A noção de indivíduo, portanto, se relaciona com um sujeito que organiza a experiência de si em torno desta vida interior e íntima, onde se passam uma série de pensamentos, emoções, lembranças e sentimentos privados.
Enquanto a subjetividade moderna estava ligada a esta dimensão privada, interiorizada, profunda e opaca, na contemporaneidade se sobrepõe a ela uma subjetividade exteriorizada, cujo foco de investimentos e cuidados é a aparência e a visibilidade. As escritas de si prosperam no âmbito público dos blogs e redes sociais e cresce o interesse tanto em expor o que era antes mantido na esfera do segredo, quanto por consumir conteúdos da intimidade alheia, descreve Sibilia (2016).
Se a topologia da subjetividade moderna estava circunscrita ao espaço privado – casa, família, intimidade, psiquismo –, “a atualidade inverte esta topologia e volta a subjetividade para o espaço aberto dos meios de comunicação e seus diversos níveis de vida exterior – tela, imagem, interface, interatividade” (Bruno, 2013, p. 81).
Como veremos na narrativa do Spotify, ao mesmo tempo que a individualidade é concebida como algo afastado da esfera pública, afirmando uma experiência de si entre sujeito e música na “privacidade”15 da relação com o aplicativo, a verdade do sujeito se desloca de uma interioridade de si para uma espécie de intimidade desenvolvida com a plataforma, que alega cada vez mais te conhecer até melhor do que você mesmo. Ainda que se trate de uma individualidade opaca, ela pode ser mapeada a partir dos rastros digitais, de modo que se desloca cada vez mais da intimidade para a “extimidade”, para usar o termo de Sibilia (2016).
5.A retórica da personalização e a campanha “Só Você”
Em artigos científicos de pesquisadores ligados ao Spotify, a promessa de personalização é defendida com base no argumento de que o gosto musical é algo extremamente íntimo e diz muito sobre cada um, refletindo momentos, lugares e pessoas importantes (Way et al, 2019). Indo além, o artigo “Just the Way You Are”: Linking Music Listening on Spotify and Personality estabelece uma relação entre os dados de escuta musical no aplicativo e traços de personalidade. Os autores afirmam que a música possui uma relação íntima com os estados emocionais e que, portanto, os “dados de streaming musical fornecem uma lente única para observar e compreender a complexidade da individualidade humana” (Anderson et al., 2020, p. 2, tradução nossa).
O argumento pressupõe que ouvir música envolve uma quantidade significativa de escolha individual e que as pessoas escutam músicas em circunstâncias distintas ao longo do dia (socializando, se exercitando, dormindo). Assim, o acúmulo de rastros digitais diários poderia ser utilizado para prever com sucesso características humanas, inclusive traços de personalidade (Anderson et al., 2020).
Mais do que discutir a validade ou legitimidade científica da pesquisa, considero interessante apontar para um certo movimento retórico da datificação: vender a ideia de que os aspectos da realidade – assim como preferências, desejos, personalidades e estados emocionais das pessoas – podem ser expressos (e calculados matematicamente) através dos dados produzidos no âmbito das plataformas digitais (Faltay, 2020). Este tipo de estudo mostra a importância de “questionar não só as plataformas, mas como a própria ciência dos dados e suas ferramentas adquirem predominância explicativa e operacional nos mais diversos contextos” (Faltay, 2020, p. 111).
Esta concepção de que as informações de consumo musical “refletem” quem as pessoas são, formulada nos artigos acadêmicos, se materializa na construção técnica dos algoritmos de recomendação e na forma como as personalizações são enunciadas pelo aplicativo. Como veremos, há toda uma retórica da personalização em que o Spotify encoraja seus usuários a acreditarem que os dados são uma expressão da individualidade (Braun, 2020), que a plataforma te conhece melhor que ninguém e que os conteúdos são feitos unicamente para você, com base no que você gosta de ouvir.

O slogan “Você é o que você ouve” sintetiza de forma direta e clara como a plataforma concebe e interpreta seus usuários. A música é entendida como um espelho, que reflete como as pessoas estão se sentindo e o que estão fazendo, de modo que “quanto mais as pessoas ouvem, melhor nós as entendemos”. Essas afirmações são emblemáticas não porque sejamos efetivamente o que ouvimos, mas por refletirem este movimento interpretativo no qual sujeitos passam a ser lidos a partir de dados digitais e análises computacionais.
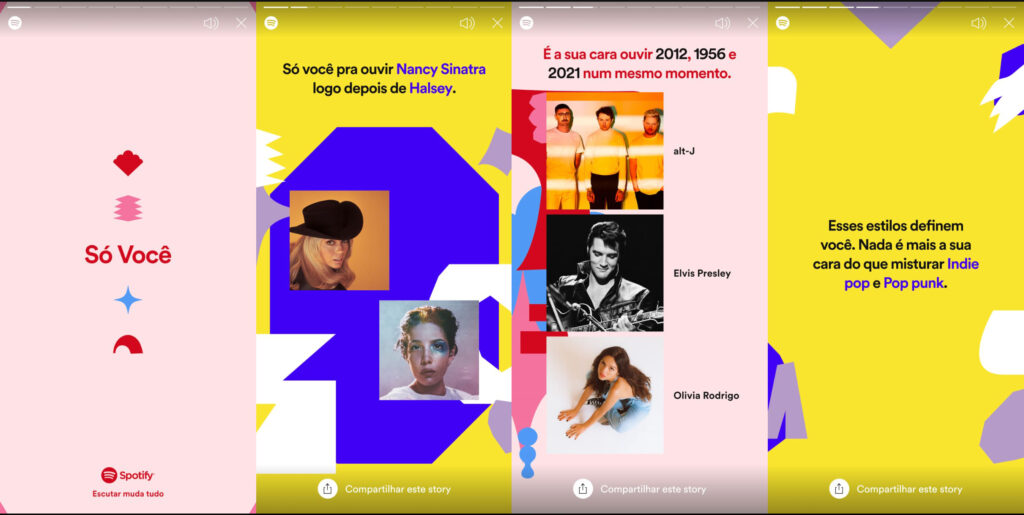
Outro exemplo emblemático que ilustra essa retórica foi a campanha Só Você, realizada em junho de 2021, que propôs uma celebração do seu estilo único de escuta.
Existem mais de 356 milhões de usuários no Spotify que sabem que ouvir é tudo. E com mais de 70 milhões de faixas e 2,6 milhões de títulos de podcast para escolher, sempre há algo novo para descobrir, compartilhar e aproveitar, mas sabemos que ninguém ouve como você. Então, hoje, estamos lançando Só Você, uma campanha global completa com uma experiência no aplicativo e listas de reprodução personalizadas que celebra exatamente isso.
“Ninguém escuta como você. E o seu jeito de escutar, só o Spotify conhece”16, dizia a divulgação da campanha no Twitter. Já na tela inicial do aplicativo, o usuário era convidado a descobrir quais artistas, músicas e podcasts são a sua cara.
Ao abrir a experiência Só Você, cada usuário recebia diversas afirmações feitas a partir de seus dados de uso da plataforma: um par musical de dois artistas muito diferentes que “só você mistura”, os três anos distintos dos quais você mais ouve músicas e os estilos musicais que “definem você”. Através de uma espécie de retrospectiva do seu gosto musical, a proposta era mostrar para cada pessoa o que diferencia ela dos outros usuários, como ela é “única” e como “ninguém escuta como você”18
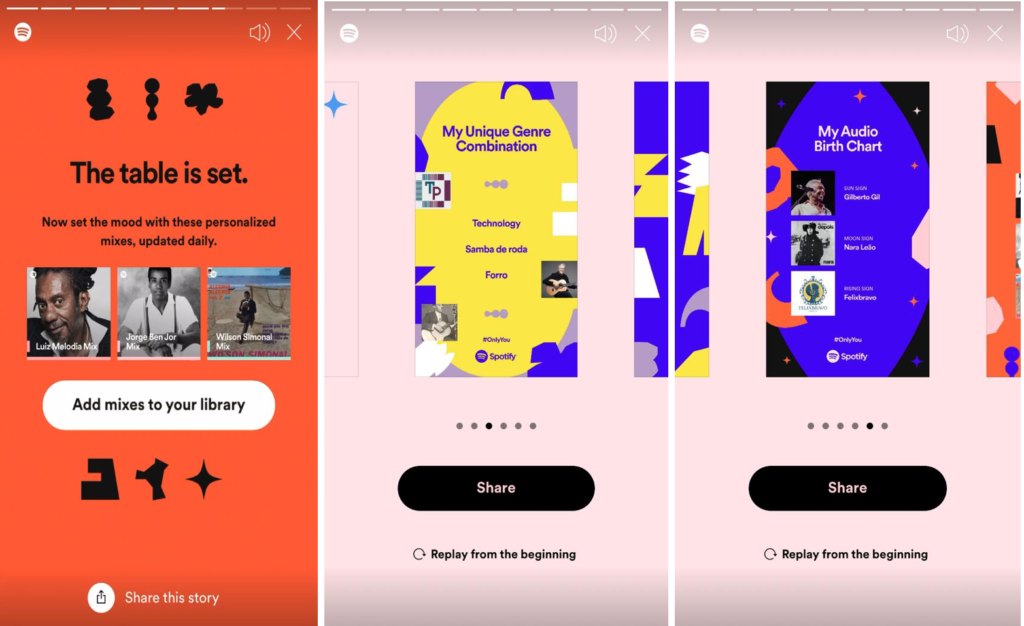
Na segunda parte da experiência, o Spotify revelava quem é o seu artista Sol (mais tocado), Lua (mais emotivo) e Ascendente (uma descoberta recente), enfatizando que “você é astrologicamente único”. A proposta de um “Mapa Astral de Áudio” novamente se relaciona a um jeito de ser e ouvir música singular para cada indivíduo. Além disso, chama a atenção a definição do artista emotivo, que remete ao interesse da plataforma em analisar traços emocionais das músicas e dos usuários19.
Ao final, cada usuário respondia a um questionário planejando um “Jantar dos sonhos” com três artistas e recebia playlists personalizadas com músicas de cada um deles, que se atualizam todos os dias. Após completar as três etapas, cada usuário ganhava também uma coleção de imagens com os resultados para serem compartilhadas nas redes sociais.
Em muitos aspectos, a experiência Só Você remete à Retrospectiva (Wrapped) que o Spotify entrega anualmente desde 2015, com as músicas, artistas e gêneros mais ouvidos, total de minutos que cada pessoa escutou de música, dentre outras informações que “definem” o seu ano20. Na retrospectiva, a plataforma também agrupa tudo em uma playlist personalizada com “As mais tocadas” e exibe as informações em um formato para ser compartilhado nas redes sociais, enfatizando como cada um tem um gosto único. Este tipo de campanha em que o Spotify mostra para o usuário alguns de seus dados de uso se tornou algo recorrente e característico das ações de personalização da plataforma.
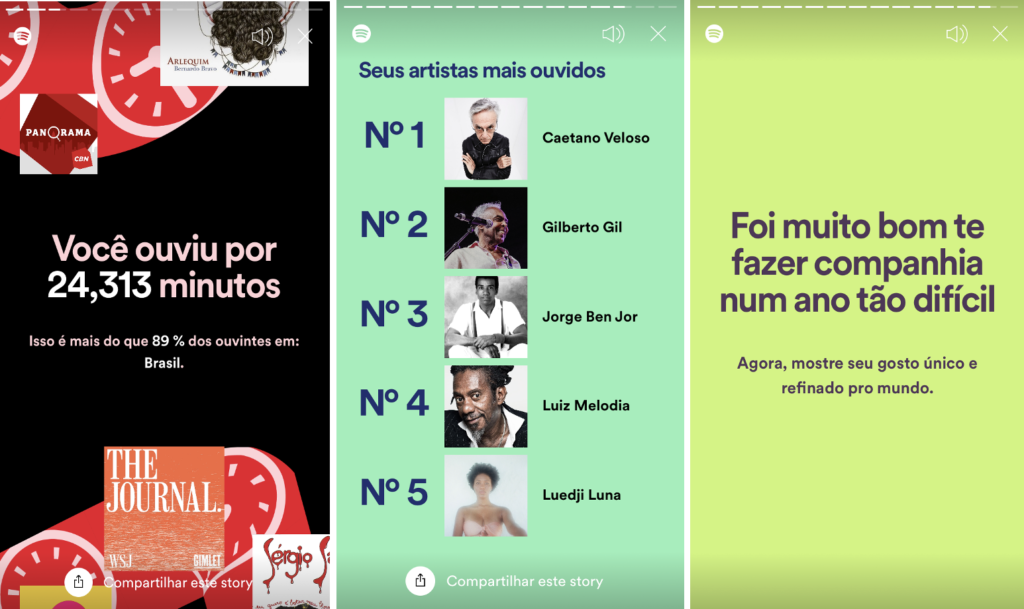
Nestas campanhas, o Spotify é capaz de transformar uma dinâmica de vigilância que captura e capitaliza as formas de consumo em algo potencialmente divertido, que procura despertar a curiosidade das pessoas. Ao convocar os usuários a verem como algoritmos os identificam e incentivá-los a compartilhar as informações com amigos, a plataforma não só normaliza como celebra o acúmulo massivo de dados pessoais (Braun, 2020). Além de se destacar de empresas concorrentes, explora também um desejo dos usuários de compartilhar, um impulso participativo e colaborativo que marca as formas de sociabilidades digitais contemporâneas (Bruno, 2013). Dessa forma, o engajamento das pessoas com as campanhas não só reitera as lógicas comerciais da empresa como possivelmente alimenta novos processos de vigilância e análise de dados.
Nos diversos exemplos mencionados, o Spotify associa a promessa de entregar personalizações bem-sucedidas à habilidade de acessar algum tipo de individualidade dos sujeitos a partir dos dados de interação online. Como diz outro slogan da empresa, não existe apenas uma experiência Spotify, “existem cerca de 365 milhões de experiências diferentes – uma para cada usuário – que são profundamente personalizadas de acordo com seus desejos e necessidades”21. Nas próximas páginas, procuraremos discutir alguns paradoxos que envolvem esta promessa de ultrapersonalização, mostrando como, na verdade, a personalização envolve uma série de generalizações. Em outras palavras, a premissa de que você, enquanto indivíduo, é distinto o suficiente para receber conteúdos com base na sua história e interesses pessoais, em larga medida não existe (Chenney-Lippold, 2017).
6. Entre perfil e sujeito: a produção de saber algorítmica
A principal disrupção que o Spotify introduz na indústria musical é a capacidade de transformar as interações humano-música em material privilegiado para segmentação de conteúdos e anúncios (Braun, 2020). Alinhado a uma lógica mais ampla do capitalismo de vigilância, “que reivindica a experiência humana como matéria-prima para práticas comerciais” (Zuboff, 2021, p. 7), o Spotify converte experiência de escuta musical em dados (Vonderau, 2019).
Ao utilizar o Spotify, cada usuário realiza diversas ações: digitar algo na barra de pesquisa, seguir um artista, pular uma música ou curtir e tocá-la várias vezes seguidas, clicar no aleatório, ouvir a playlist recomendada, etc. É a partir de cada uma dessas ações, e dos dados que são gerados delas, que a plataforma constrói perfis de gostos, hábitos e comportamentos, agregados em uma enorme escala de mais de 500 milhões de usuários22. Todas essas informações de interação são interpretadas como classificações implícitas, substituindo sistemas prévios de classificação como aqueles em que o usuário avaliava o conteúdo que lhe era recomendado em um ranking de 1 a 5 estrelas. Em um movimento interpretativo herdado do behaviorismo, estes dados, abundantes e constantemente atualizados, passaram a ser considerados mais verdadeiros que as próprias classificações explícitas dos usuários (Seaver, 2018).
Este é um ponto importante do paradigma da datificação: as ciências comportamentais se consolidaram como um modelo epistemológico privilegiado para explicar e intervir no comportamento humano através de técnicas algorítmicas (Bentes, 2022). Aliado aos objetivos de engajamento das empresas, o chamado design comportamental instrumentalizou técnicas voltadas para influenciar, persuadir, explorar vulnerabilidades cognitivas e emocionais, bem como padrões automáticos de comportamentos em plataformas digitais (Bentes, 2022, p. 123). Com o uso de big data, foi capaz de atualizar e aprimorar algumas técnicas do behaviorismo radical de Skinner.
Nesta matriz comportamental, rastros digitais tornaram-se via privilegiada de produção de conhecimento sobre os sujeitos. Os dados de interação com as redes passaram a ser considerados mais verdadeiros ou autênticos do que as informações explícitas do que fornecemos, uma vez que se trataria de uma forma de conhecimento “objetiva”, que antecede qualquer intenção e subjetividade (Rouvroy e Berns, 2015).
É a partir destes pressupostos que se consolida a ideia, mencionada anteriormente, de que algoritmos seriam capazes de “nos conhecer” melhor do que nós mesmos. O sentido de conhecer, entretanto, não tem a ver com produzir um saber aprofundado sobre indivíduos identificáveis, mas fazer uma previsão suficientemente boa para influenciar ou desencadear determinada ação. O valor dos fluxos de dados não está tanto em dizer quem somos ou o que nossos dados dizem sobre nós, mas no que pode ser inferido sobre quem podemos ser (Amoore, 2011, p. 28), isto é, em seu potencial preditivo.
Quanto a isso, torna-se importante também enfatizar que a geração de perfis de usuário é traçada a partir de categorias supraindividuais, padrões e correlações de afinidade e similaridade reconhecidos em um conjunto de dados em larga escala (Rouvroy e Berns, 2015). Apesar de o perfil funcionar como uma representação de cada usuário, ele não diz respeito somente a um indivíduo identificável, uma vez que o conhecimento que embasa as recomendações não se restringe ao que cada indivíduo escuta em seu aplicativo. Os perfis de usuários são elaborados a partir de grandes conjuntos de dados anonimizados, fragmentados, desvinculados dos indivíduos a que se referem e agregados a partir da identificação de padrões de similaridade e correlações.
Dessa forma, os processos de perfilamento consistem muito mais em elaborar modelos probabilísticos de comportamentos, trajetórias, hábitos e interesses em larga escala para agir sobre você e seus similares (Lury e Day, 2019). Ninguém corresponde totalmente a um perfil, assim como nenhum perfil visa unicamente uma pessoa específica – mais do que produzir um saber individualizado e aprofundado, o objetivo é projetar desejos, comportamentos, escolhas ou intenções futuras (Bruno, 2013).
Apesar da lógica algorítmica constantemente apelar para o indivíduo como alvo de suas recomendações supostamente ultrapersonalizadas, ela opera muito mais na dimensão das dividualidades (Deleuze, 2013; Bruno, 2013; Rodriguez, 2015). Não se trata da produção de um conhecimento individualizado, único e aprofundado sobre indivíduos específicos e identificáveis, mas de usar um conjunto de informações e correlações interpessoais para agir sobre seus similares (Bentes, 2019).
É por isso que a ideia de “personalização” – a premissa de que você, como um usuário, é distinto o suficiente para receber conteúdos baseados em você como uma pessoa, com uma história e interesses individuais – em grande medida não existe. Ao invés disso, somos comunicados através do perfilamento, por interseções de significados categóricos que permitem com que nossos dados, mas não necessariamente nós, sejam ‘generizados’, ‘racializados’ e ‘classializados’23 (Chenney-Lippold, 2017 p. 125).
Como aponta Wendy Chun (2016), o ‘você’ para quem as recomendações algorítmicas se referem é simultaneamente singular e plural, específico e generalizável, único e igual a todo mundo.
7. Reconfigurações subjetivas e a construção de identidades algorítmicas
Nesta lógica algorítmica de produção de saber, a autenticidade não está no que o indivíduo fala para os outros ou no entendimento que tem de si, mas na forma como se comporta, nas músicas e podcasts que escuta, em tudo aquilo que pode ser medido e calculado computacionalmente sobre ele. Na medida que as maneiras de ver o sujeito estão se deslocando, me parece que o próprio entendimento do que é sujeito está passando por transformações: para o Spotify, “você é o que você ouve”.
Para além de refletir uma reconfiguração entre as fronteiras de público e privado, este movimento interpretativo no qual somos lidos a partir de dados e modelos preditivos redefine os próprios termos da identidade online, como argumenta Chenney-Lippold no livro We Are Data: Algorithms and the Making of Our Digital Selves (2017). Para o autor, quem nós somos não é apenas o que pensamos ser, mas tudo aquilo que os sistemas inferem sobre nós a partir de cálculos computacionais (Chenney-Lippold, 2017).
Assim, ao mesmo tempo que a personalização transmite a ideia de que estamos sendo vistos pelo que realmente somos – indivíduos com gostos e preferências distintas e singulares –, o que plataformas como o Spotify produzem são modos específicos de ver e compreender o indivíduo, alinhados com seus objetivos comerciais e modelos de negócio (Prey, 2018, p. 1087). O conhecimento que molda o mundo e nós mesmos online está cada vez mais sendo construído por algoritmos, dados e as lógicas neles inseridas, que categorizam as pessoas sem a sua participação direta ou consentimento.
Organizando a ordem em que postagens, conteúdos e anúncios aparecem, sistemas algorítmicos alteram profundamente a experiência que cada um tem nos ambientes digitais, incentivando tendências, definindo o que ganha destaque e o que permanece fora do alcance dos usuários (Kitchin, 2017). Mas apesar de se apresentar como uma produção de saber objetiva, neutra e a-normativa, capaz de “apreender” a realidade como tal (Rouvroy e Berns, 2015), a racionalidade algorítmica opera a partir de objetivos que estão longe da neutralidade.
Nossos comportamentos jamais foram tão conduzidos – observados, registrados, classificados, avaliados – como agora com esta base estatística, e isto com base e em função de códigos de inteligibilidade e critérios absolutamente opacos à compreensão humana (Rouvroy e Berns, 2015, p. 44).
Os dados não falam por si mesmos, mas são “feitos para falar”24, enfatiza Chenney-Lippold (2017), no sentido de que adquirem estatuto de verdade para dizer algo sobre nossos gostos, preferências, desejos, até mesmo emoções e personalidades. Quem fala pelos dados, argumenta o autor, detém o poder de enquadrar como passamos a nos compreender e a compreender nosso lugar no mundo. O que ele aponta ao longo do livro é para o perigo epistemológico da vida passar a ser compreendida por meio de uma vigilância onipresente e dos perfis algorítmicos serem concebidos como a própria identidade dos indivíduos.
As identidades projetadas na forma destes perfis, entretanto, não dependem de vínculos profundos ou de um espelhamento fiel com os indivíduos a que se referem. Não se trata de identidades previamente “dadas”, mas que se tornam “reais” ou “efetivas” na sua função antecipatória, na medida que indivíduos se identificam ou se reconhecem no perfil antecipado e acatam algum tipo de comportamento ou escolha (Bruno, 2006).
Quando, por exemplo, aceito uma oferta personalizada de produto que eu nem mesmo sabia existir ou que não havia desejado previamente, torno efetivo o perfil ou identidade que me foi antecipado e, ao mesmo tempo, reforço-o para futuras previsões tanto a meu respeito quanto a respeito de outros indivíduos que habitam bancos de dados similares (Bruno, 2006, p. 157).
Diversos autores do campo dos “estudos críticos de algoritmos” (Gillespie e Seaver, 2016) têm apontado que as projeções algorítmicas possuem efeitos altamente performativos (Introna, 2013; Mackenzie, 2005; Bucher, 2017; Bharti, 2021). Mais do que revelar identidades, desejos ou necessidades prévias dos usuários, os perfis de gosto atuam como antecipações performativas, capazes de influenciar o comportamento desses usuários através das recomendações oferecidas. Neste sentido, as identidades algorítmicas que nos são atribuídas não atendem a critérios de verdade ou falsidade, mas são simulações pontuais com uma efetividade performativa, que pretendem aumentar a probabilidade de algo que seria apenas uma potencialidade (Bruno, 2013, p. 169).
Não temos um gosto musical completamente pré-estabelecido e não há uma única resposta certa ou errada para o que vamos querer ouvir, apesar de certamente haver tendências e preferências. O objetivo da personalização, assim, “não é tanto adaptar a oferta aos desejos espontâneos (se ao menos algo assim existir) dos indivíduos, mas, em vez disso, adaptar os desejos dos indivíduos à oferta” (Rouvroy e Berns, 2015, p. 44). As recomendações algorítmicas atuam justamente suscitando aqueles desejos de consumo que alegam descobrir ou revelar.
Nesse contexto, o processo do sujeito se identificar ou se reconhecer no perfil antecipado pode possivelmente contribuir para a própria eficácia da recomendação. Lury e Day (2019) chamam isso de “reconhecimento familiar”, isto é, a impressão que a personalização algorítmica passa de te conhecer melhor do que você mesmo. As autoras descrevem o funcionamento da personalização como um loop recursivo, no qual não só o perfil de usuário está sempre se ajustando aos novos dados produzidos pelos indivíduos, mas o próprio indivíduo é reformulado pelos perfis em que é enquadrado (Faltay, 2020, p. 142).
Robert Prey (2018) afirma algo similar quando diz que, mais do que questionar se estes serviços “acertaram” em suas recomendações, importa pensar como as mídias personalizadas nos levam a performar um sujeito datificado. Na relação com estas práticas e saberes algorítmicos, tornamo-nos copos estatísticos, sujeitos influenciáveis, reduzidos à probabilidade de agir de forma similar a outros indivíduos com perfis parecidos com os nossos. Considerando que o sujeito não é uma entidade com gostos e desejos previamente determinados, talvez o problema da personalização algorítmica seja justamente restringir as possibilidades diversas do que podemos vir a ser, reduzindo o contato com conteúdos díspares, imprevistos ou que nos desloquem de nossos enraizamentos. A construção de identidades algorítmicas, portanto, implicaria sujeitos cada vez mais previsíveis e iguais uns aos outros.
Considerando estas questões, torna-se interessante explorar o modo como os usuários se relacionam com estas ferramentas algorítmicas de recomendação. A noção de imaginários algorítmicos, de Taina Bucher (2017), aponta justamente para as formas como as pessoas dão sentido aos algoritmos, para os modos de pensar sobre o que algoritmos são, como funcionam e como estas imaginações, por sua vez, possivelmente afetam o uso dessas plataformas. De forma parecida, a ideia de teorias folk remete a teorias intuitivas e informais que as pessoas elaboram para explicar os funcionamentos, efeitos e consequências destes sistemas tecnológicos (Siles et al., 2020). Ambos os conceitos consideram que entender como as pessoas dão sentido e se relacionam com os processos de datificação contribui não só para entender o fenômeno como um todo, mas também para entender os usos específicos que são feitos de cada plataforma.
No caso do Spotify, podemos pensar em que medida a retórica da personalização mobilizada pela empresa contribui para solidificar, nos usuários, a premissa de que o aplicativo sabe o que você gosta e vai querer ouvir a cada momento do dia. A hipótese aqui levantada é que, ao reforçar a ideia de que o algoritmo funciona ou acerta em suas recomendações porque “conhece” os gostos individuais de cada um, o Spotify possivelmente contribui para que aquela previsão se confirme, isto é, para sua eficácia performativa.
Considerações finais
Este artigo buscou apresentar como as estratégias de personalização ganharam uma centralidade no aplicativo Spotify, com foco especial na forma como a empresa anuncia e concebe as ferramentas de recomendação algorítmica que emprega para customizar a experiência de uso do app. Para isso, nos debruçamos sobre materiais institucionais, peças publicitárias e campanhas da plataforma.
Ao longo do texto, apontamos algumas facetas dos sistemas de recomendação. Ao mesmo tempo que se legitimam através de um discurso de facilitar e trazer uma experiência mais satisfatória com o aplicativo, eles atuam como “armadilhas” para capturar a atenção de usuários inconstantes ou indecisos, atuando em favor dos interesses comerciais da empresa. Além disso, operam de acordo com uma lógica que tende a priorizar critérios de familiaridade e semelhança, de modo que tendem a homogeneizar os padrões de consumo, reforçando gostos e hábitos já estabelecidos e dificultando o contato com conteúdos que fogem do padrão.
Nos materiais observados, destacamos em especial como a promessa de personalização se sustenta a partir da premissa de que os algoritmos seriam capazes de “conhecer” as pessoas melhor do que amigos, familiares ou até elas mesmas. Chamamos atenção para uma certa retórica da personalização, na qual o Spotify associa as tecnologias algorítmicas ao discurso de que cada usuário faz um uso singular da plataforma, capaz de ser mapeado e compreendido pela coleta e análise de dados digitais.
Assim, traçamos uma relação entre os mecanismos de recomendação e personalização algorítmica com algumas transformações no nível das subjetividades contemporâneas, sobretudo no que se refere às ideias de intimidade e individualidade.
Se há uma individualidade vinculada a este tipo de rastro e ao conhecimento que se pretende gerar a partir dele, ela é menos da ordem do passado que do futuro, menos da ordem da interioridade que da exterioridade, menos relativa a uma singularidade do que a regras de similaridade (Bruno, 2013, p. 163).
Neste sentido, buscamos refletir sobre como os algoritmos classificatórios também redefinem as próprias ideias em torno da identidade, isto é, transformam como os indivíduos entendem a si mesmos e seus próprios gostos e desejos (Chenney-Lippold, 2017; Bucher, 2017). Mais do que revelar uma identidade ou individualidade previamente estabelecida, a personalização opera de forma performativa, nos levando a performar as identidades algorítmicas que nos são atribuídas. A construção do sujeito datificado, portanto, tem menos a ver com quem nós somos e mais com quem podemos ser.
Estas ideias, que aqui assumem um caráter ainda especulativo, poderão ser exploradas em pesquisas futuras através de entrevistas com usuários do Spotify, de modo a aprofundar o entendimento de como eles efetivamente se sentem e se relacionam com as recomendações algorítmicas. Em outras palavras, se as pessoas se sentem entendidas pelo Spotify tanto quanto o app alega entendê-las.
Referências bibliográficas
Amoore, L. (2011). Data derivatives: On the emergence of a security risk calculus for our times. Theory, Culture & Society, 28(6), 24–43. https://doi.org/10.1177/0263276411417430
Anderson, I., Gil, S., Gibson, C., et al. (2020). “Just the way you are”: Linking music listening on Spotify and personality. Social Psychological and Personality Science, 12(4), 561–572. https://doi.org/10.1177/1948550620923228
Bharti, N. (2021). Engaging Critically with Algorithms: Conceptual and Performative Interventions. Science, Technology, & Human Values, 47(4). https://doi:10.1177/01622439211015296
Braun, T. A. (2020). “Dance like nobody’s paying”: Spotify and Surveillance as the Soundtrack of Our Lives. (Master’s Dissertation, University of Western Ontario). Disponível em: https://ir.lib.uwo.ca/etd/7001/
Bentes, A. (2019). A gestão algorítmica da atenção: enganchar, conhecer e persuadir. In Polido, F. B. P.; Anjos, L. C.; Brandão, L. C. C. (Eds.), Políticas, internet e sociedade (pp. 222-234). IRIS.
Bentes, A. C. F. (2022). Da Madison Avenue ao Vale do Silício: ciências comportamentais do engajamento, tecnologias de influência e economia da atenção (Doctoral dissertation, Escola de Comunicação, Universidade Federal do Rio de Janeiro). Disponível em: http://www.pos.eco.ufrj.br/site/teses_dissertacoes_interna.php?tease=23
Bruno, F. (2006). Dispositivos de vigilância no ciberespaço: duplos digitais e identidades simuladas. Revista Fronteira (UNISINOS), 8, 152-159. http://revistas.unisinos.br/index.php/fronteiras/article/view/6129
Bruno, F. (2013). Máquinas de ver, modos de ser: vigilância, tecnologia e subjetividade. Sulina.
Bucher, T. (2017). The algorithmic imaginary: exploring the ordinary affects of Facebook algorithms. Information, Communication & Society, 20(1). https://doi.org/10.1080/1369118X.2016.1154086
Caliman, L. (2012). Os regimes da atenção na subjetividade contemporânea. Arquivos Brasileiros de Psicologia, 64(1), 02-17. http://pepsic.bvsalud.org/scielo.php?script=sci_abstract&pid=S1809-52672012000100002
Ciocca, S. (n.d.). How Does Spotify Know You So Well? – Featured Stories. Medium. Retrieved November 10, 2021, from https://medium.com/s/story/spotifys-discover-weekly-how-machine-learning-finds-your-new-music-19a41ab76efe
Chenney-Lippold, J. (2017). We are Data: algorithms and the making of our digital selves. NYU Press.
Chun, W. H. K. (2016). Updating to remain the same: Habitual new media. MIT Press.
Deleuze, G. (2013). Post-scriptum sobre as sociedades de controle. In Conversações (3a ed., pp. 219–226). Ed. 34.
Dieleman, S. (2014). Recommending music on Spotify with deep learning. Retrieved July 12, 2020, from https://sander.ai/2014/08/05/spotify-cnns.html
Eriksson, M., Fleisher, R., Johansson, A., Snickars, P., & Vonderau, P. (2019). Spotify Teardown: Inside the Black Box of Streaming Music. MIT Press.
Faltay, P. (2020). Máquinas paranoides e sujeito influenciável: conspiração, conhecimento e subjetividade em redes algorítmicas. (Doctoral dissertation, Escola de Comunicação, Universidade Federal do Rio de Janeiro). Disponível em: http://hdl.handle.net/11449/197026
Foucault, M. (2016). Microfísica do Poder. Paz e Terra.
Galvanize. (2016, August 22). Ever Wonder How Spotify Discover Weekly Works? Data Science. Galvanize Blog. Retrieved February 18, 2022, from https://www.galvanize.com/blog/spotify-discover-weekly-data-science/
Gillespie, T., Seaver, N. (2015). Critical Algorithm Studies. A Reading List. https://socialmediacollective.org/reading-lists/critical-algorithm-studies/
Gomez-Uribe, C., & Hunt, N. (2015). The Netflix recommender system: Algorithms, business value, and innovation. ACM Trans. Manage. Inf. Syst., 6(4), Article 13. https://doi.org/10.1145/2843948
Hesmondhalgh, D., Valverde, R. C., Kaye, D. B. V., Li, Z. (2023). The impact of algorithmically driven recommendation systems on music consumption and production – a literature review. https://www.gov.uk/government/publications/research-into-the-impact-of-streaming-services-algorithms-on-music-consumption/the-impact-of-algorithmically-driven-recommendation-systems-on-music-consumption-and-production-a-literature-review
Holtz, D., Carterette, B. Chandar, P., Nazari, Z., Cramer, H., & Aral, S. (2020). The Engagement-Diversity Connection: Evidence From a Field Experiment on Spotify. In Proceedings of the 21st ACM Conference on Economics and Computation (EC ’20). New York, NY, USA. https://doi.org/10.1145/3391403.3399532
Internetlab. (2023). Algo_Ritmos. https://algoritmos.internetlab.org.br/
Introna, L. (2013). Algorithms, performativity and governability (early draft). In: Governing Algorithms: a conference on computation, automation and control, New York. http://governingalgorithms.org/wp-content/uploads/2013/05/3-paper-introna.pdf
Kitchin, R. (2017). Thinking critically about and researching algorithms. Information, Communication & Society, 20(1), 14-29. https://doi.org/10.1080/1369118X.2016.1154087
Lury, C., & Day, S. (2019). Algorithmic Personalization as a Mode of Individuation. Theory, Culture & Society, 36(2), 17–37. https://doi.org/10.1177/0263276418818888
Mackenzie, A. (2005). The Performativity of Code: Software and Cultures of Circulation. Theory, Culture & Society, 22(1). https://doi.org/10.1177/0263276405048436
Parisier, E. (2012). The Filter Bubble: What the Internet is Hiding from You. Penguin.
Prey, R. (2018). Nothing personal: algorithmic individuation on music streaming platforms. Media, Culture & Society, 40(7), 1086–1100. https://doi.org/10.1177/0163443717745147
Rodriguez, P. E. (2015). Espetáculo do Dividual: Tecnologias do eu e vigilância distribuída nas redes sociais. Revista ECO-Pós, 18(2), 57–68. https://revistaecopos.eco.ufrj.br/eco_pos/article/view/2680
Rouvroy, A., & Berns, T. (2015). Governamentalidade Algorítmica e perspectivas de emancipação: o díspar como condição de individuação pela relação?. Revista ECO Pós, 18(2). https://revistaecopos.eco.ufrj.br/eco_pos/article/view/2662
Seaver, N. (2018). Captivating algorithms: Recommender systems as traps. Journal of Material Culture, 24(4), 421–436. https://doi.org/10.1177/1359183518820366
Sibilia, P. (2016). O show do eu. Contraponto.
Siles, I., Segura-Castillo, A., Solís, R., Sancho, M. (2020). Folk theories of algorithmic recommendations on Spotify: Enacting data assemblages in the global South. Big Data & Society, online. https://doi.org/10.1177/2053951720923377
Spotify Advertising. (2020). Cinco anos de descoberta e engajamento por meio das Descobertas da Semana. https://ads.spotify.com/pt-BR/noticias-insights/cinco-anos-de-descoberta-e-engajamento-por-meio-das-descobertas-da-semana/
Spotify Advertising. (2021). The guide to creating digital audio ads. Seção 2: Contexto importa. https://ads.spotify.com/pt-BR/guide-to-creating-audio-ads/context/
Van Djick, J. (2017). Confiamos nos dados? As implicações da datificação para o monitoramento social. MATRIZes, 11(1), 39-59. https://doi.org/10.11606/issn.1982-8160.v11i1p39-59
Vonderau, P. (2017). The Spotify Effect: Digital Distribution and Financial Growth. Television & New Media, 20(1), 3–19. https://doi.org/10.1177/1527476417741200
Thompson, N. (2023, March 14). When Tech Knows You Better Than You Know Yourself. WIRED. https://www.wired.com/story/artificial-intelligence-yuval-noah-harari-tristan-harris/
Way, S. F., Anderson, I., Gil, S., & Clauset, A. (2019). Environmental changes and the dynamics of musical identity. Spotify Research. https://research.atspotify.com/environmental-changes-and-the-dynamics-of-musical-identity
Walter, B. E. P., & Hennigen, I. (2021). Problematizando a governamentalidade algorítmica a partir do sistema de recomendação da Netflix. Psicologia & Sociedade, 33. https://doi.org/10.1590/1807-0310/2021/2020033
Werner, A. (2020). Organizing music, organizing gender: algorithmic culture and Spotify recommendations, Popular Comunication, 18(1). https://doi.org/10.1080/15405702.2020.1715980
Zuboff, S. (2020). A era do capitalismo de vigilância: A luta por um futuro humano na nova fronteira do poder. Intrínseca.